


The Evolution from Databricks Lakehouse to the Data Intelligence Platform





Introduction
Organizations have long struggled with the limitations of traditional data warehouses and data lakes in the realm of data storage and analytics. To address these limitations, the lakehouse paradigm emerged, pioneered by Databricks. The Databricks Lakehouse architecture combines the best features of both data warehouses and data lakes into a unified, cloud-based system. This approach aims to eliminate data silos, simplify management, and allow organizations to converge their workloads under a single platform with standardized governance policies.
This article explores how the Databricks Lakehouse platform overcomes these challenges by integrating the features of data warehouses and data lakes into a single, cohesive cloud solution. This unified approach helps break down data silos, simplifies data management, and empowers different data users within an organization to collaborate seamlessly.
We will also examine how integrating Generative AI (GenAI) into the Databricks platform has transformed user experiences. The Databricks Data Intelligence Platform combines the power of AI with the scalability and flexibility of the Databricks ecosystem, providing organizations with a comprehensive solution to unlock the full potential of their data.
Historical Perspective And The Emergence Of The Lakehouse Architecture
The Rise of Data Warehouses
Data warehouses have been pivotal in business intelligence and analytics for many years. They excel at storing and processing large amounts of structured data, such as customer transactions, product sales, and financial records. These systems are designed to handle complex queries and reporting, making them an ideal choice for business users who require data analysis to make informed decisions. However, data warehouses struggle with unstructured and semi-structured data, such as social media posts, images, and videos.
The Emergence of Data Lakes
The rise of machine learning (ML) and artificial intelligence (AI) further exposed the limitations of traditional data warehouses. These technologies require vast and varied datasets to train models and generate predictions, which are often unstructured or semi-structured. Traditional data warehouses are not optimized to handle these types of data efficiently.
In response to these challenges, data lakes emerged as a flexible solution. A data lake is a centralized repository designed to store all types of data, regardless of structure or format. With their scalability and flexibility, data lakes are well-suited for managing the diverse data needs of machine learning and AI.
Challenges of Data Lakes
While data lakes offer flexibility, they come with several challenges. A significant issue is the lack of transactional support and data quality management. Data lakes are not built to handle high transaction volumes, making it challenging to ensure that the data is accurate and consistent.
Another major challenge with data lakes is the absence of proper governance and reliability. Data lakes often lack metadata and data lineage, which are critical for ensuring that data is used correctly and effectively. This lack of governance makes it difficult for businesses to trust the data and use it confidently for decision-making.
The Rise of Hybrid Data Architectures
Due to these challenges, many organizations found that their data lakes quickly became “data swamps”—unmanageable repositories filled with unreliable data. To solve these issues, businesses began adopting hybrid data architectures that combine the benefits of both data warehouses and data lakes. Hybrid architectures allow organizations to store structured data in a data warehouse while leveraging data lakes for unstructured and semi-structured data. This approach maximizes the value of both systems and reduces the limitations of each.
Despite these efforts, organizations were left managing two separate systems—data warehouses for BI applications and data lakes for AI/ML—which resulted in data silos and governance challenges.
The Need for a Unified Approach
Maintaining distinct systems for BI and ML increased both operational complexity and costs. Organizations needed to manage and maintain multiple tools, infrastructure, and skill sets, which put a strain on resources and hampered innovation.
To address these challenges, enterprises sought a unified infrastructure that could manage all types of data throughout their lifecycle while supporting various analytics use cases. This unified approach is needed to overcome the limitations of traditional data warehouses and data lakes, providing a cohesive, scalable, and flexible solution.
In the realm of data storage and analytics, organizations have long grappled with the limitations of traditional data warehouses and data lakes. Seeking an alternative that could bridge the gap between these two systems, a new paradigm emerged: the lakehouse.
Pioneered by Databricks, the lakehouse architecture aimed to combine the best features of both data warehouses and data lakes into a unified, cloud-based system. By doing so, it aimed to break down silos, simplify management, and enable organizations to converge their workloads under a single platform with standardized governance policies.
One of the key benefits of the lakehouse approach is that it provides a single, holistic view of information at scale. This enables organizations to gain deeper insights from their data and power advanced analytics more effectively. With the cloud infrastructure’s inherent scalability, the lakehouse allows organizations to run more complex solutions on their data than ever before.
The lakehouse architecture is designed to handle various types of data, both structured and unstructured. This flexibility makes it an ideal platform for organizations that need to store and analyze large volumes of diverse data, such as IoT sensor data, social media data, and customer transaction data.
Moreover, the lakehouse’s open-source nature allows organizations to customize and extend the platform to meet their specific requirements. This flexibility makes it a popular choice for organizations that want to build custom data pipelines and applications.
By combining the strengths of data warehouses and data lakes, the lakehouse offers organizations a powerful platform for data storage, analytics, and machine learning. As more organizations embrace the cloud and look for ways to extract maximum value from their data, the lakehouse is poised to become a critical tool for digital transformation.
Image Source: Databricks
What is the Databricks Lakehouse?
The Databricks Lakehouse platform is a comprehensive data architecture that provides organizations with the foundation for their data intelligence initiatives. Built on open source and open standards, the Databricks Lakehouse architecture simplifies data management by eliminating silos and enabling all data personas within an organization to collaborate and build a variety of use cases.
At the core of the Databricks Lakehouse platform is the cloud object storage (S3-AWS, ADLS-Azure, and GCP), which serves as the central data store. This enables organizations to store enormous volumes of structured, semi-structured, or unstructured data in their native formats in one of the most cost-effective storage options available on the cloud. This constitutes the “lake” in the lakehouse architecture.
Once data lands in the cloud, it is moved to the Delta Lake format. Delta Lake is an open-source storage layer that brings performance, reliability, and governance to data lakes. Delta Lake applies atomic transactions, caching, indexing, and time travel to make large-scale storage reliable and performant for mission-critical workloads. It essentially provides data warehouse capabilities to the data stored in cloud storage, thus forming the “house” in the lakehouse architecture.
The key features of the Databricks Lakehouse platform include:
- Delta Lake: The open-source format for optimizing the storage of massive volumes of structured, semi-structured, and unstructured data for reliability, performance, and governance.
- Unified Batch and Streaming: Databricks supports both batch and real-time data processing through the same platform using Spark Structured Streaming. This allows organizations to combine historical data with streaming data for real-time insights and analytics.
- Unity Catalog: Captures metadata and usage information across diverse data types and storage systems for unified discovery and governance. Unity Catalog provides a single point of access for data discovery, lineage tracking, and security management, making it easier for organizations to understand their data landscape and ensure compliance with data regulations.
- Multi-lingual Support: The platform supports popular languages such as SQL, Python, R, Java, and Scala, enabling data engineers, data scientists, and business analysts to work on the same data using their preferred tools and languages. This fosters collaboration and knowledge sharing across different teams within an organization.
- Cloud-native architecture: Databricks utilizes managed cloud infrastructure, automating resource management and scaling to handle even the most resource-intensive workloads.
- Secure and governed access: Stringent oversight and granular auditing are ensured through comprehensive access controls, encryption, and data masking.
- Autoscaling and collaboration: Data scientists can efficiently scale their work to production while fostering close collaboration with business users through shared dashboards, reports, and applications.
The Databricks Lakehouse platform provides a powerful and flexible foundation for organizations to build a modern data architecture that supports a wide range of data workloads and use cases. By leveraging the combined capabilities of cloud object storage, Delta Lake, Spark Structured Streaming, Unity Catalog, and multi-lingual support, organizations can unlock the full potential of their data and drive better business outcomes.
Image Source: Databricks
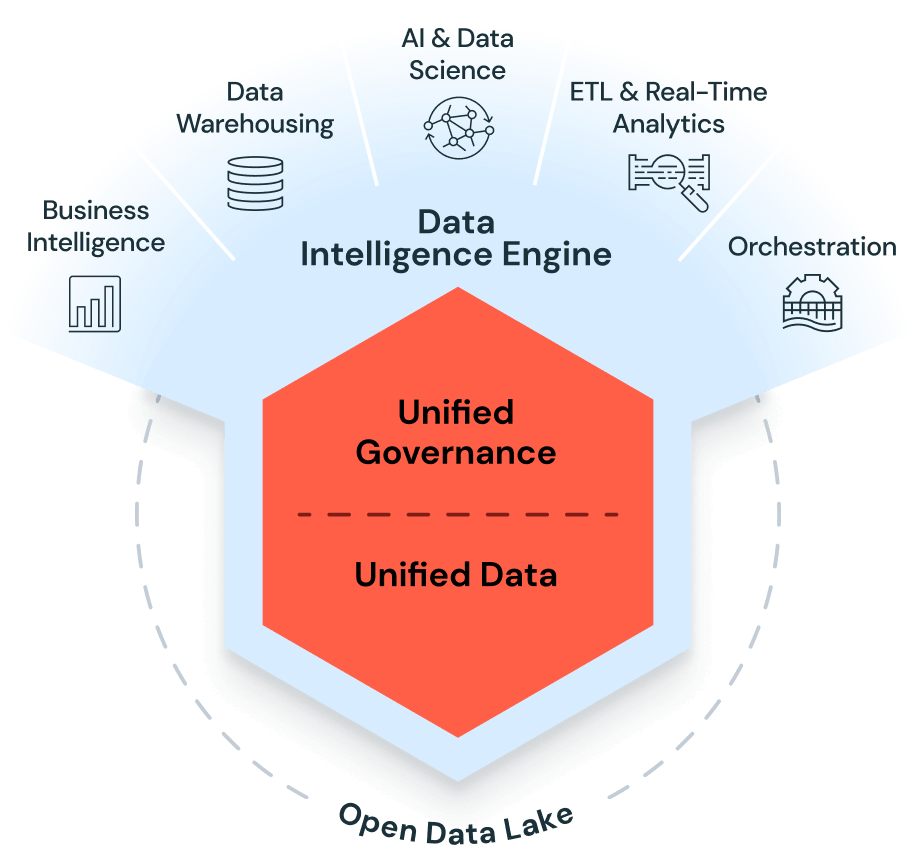
What is the Databricks Data Intelligence Platform?
2023 witnessed a transformative year with the unprecedented rise of Generative AI Large Language Models (GenAI LLMs). Databricks, a pioneering leader in data management and analytics, was strategically positioned to capitalize on this groundbreaking technology. Databricks revolutionized its platform by seamlessly integrating the lakehouse architecture with GenAI capabilities, creating a transformative data intelligence platform that empowers organizations to unlock unprecedented value from their data.
Databricks leveraged GenAI capabilities in every aspect of its platform, from assisting developers in writing code, troubleshooting, and automatically generating insights from data. This seamless integration enabled developers to create and deploy AI-powered applications with unprecedented speed and agility. Moreover, Databricks built capabilities and features within the platform that empower organizations to build their own GenAI use cases. Features like Vector Search, the Fine-Tuning API, and RAG Studio enable organizations to productize their GenAI use cases, from creating customized RAG applications to building their own models from scratch using their proprietary data.
By seamlessly integrating GenAI capabilities across the entire platform, Databricks created the Databricks Data Intelligence Platform. This revolutionary platform harnesses the power of GenAI to automate and augment every step of the data lifecycle, from data ingestion and processing to analysis and visualization. Databricks leveraged the latest GenAI models and technology to develop the Data Intelligence Engine (Databricks IQ), which acts as the central nervous system of the platform, powering all its components.
With Mosaic ML and Databricks IQ, developers can now create their own workloads and applications with the expertise of subject matter experts like never before. Databricks AI empowers data scientists to harness large language models as they are, enriching them with their domain-specific knowledge using RAG, fine-tuning with more specialized knowledge, or even training a new LLM from scratch. The Databricks Data Intelligence platform propels Databricks into a new era, empowering organizations to create the next generation of data and AI applications with unmatched quality, speed, and agility.
The Databricks Data Intelligence Platform transformed how organizations leverage data and AI. By seamlessly integrating GenAI capabilities, Databricks created a platform that automates and augments every step of the data lifecycle. Organizations can now unlock unprecedented value from their data, gain deeper insights, make better decisions, and drive innovation like never before. The future of data and AI is here, and Databricks is leading the charge with its groundbreaking Data Intelligence Platform.
Summary
Databricks is a leader in data management and analytics, and its Data Intelligence Platform is a game-changer for organizations looking to leverage data and AI to drive business outcomes. With its seamless integration of GenAI capabilities, Databricks Data Intelligence Platform empowers organizations to create the next generation of data and AI applications with unmatched quality, speed, and agility.







